Our Journey to the Top of CUREBench@NeurIPS 2025: A Deep Dive into Medical AI Benchmarking
Published on October 24, 2025 • 12 min read
We're excited to share that UniBio Intelligence achieved top rankings on the public leaderboard of the CUREBench@NeurIPS 2025 competition, a rigorous benchmark designed to evaluate AI systems' capabilities in medical question answering and clinical reasoning. This post details our approach, the challenges we faced, and the insights we gained while building robust medical AI systems.
Understanding CUREBench: A New Standard for Medical AI
CUREBench (Clinical Understanding and Reasoning Evaluation Benchmark), hosted on Kaggle, is a comprehensive benchmark colocated with NeurIPS 2025 that evaluates large language models on their ability to answer complex medical questions requiring clinical reasoning, diagnostic skills, and knowledge synthesis. CUREBench joins other important medical AI benchmarks like MedQA and MedMCQA [5,6] in advancing the evaluation of AI systems for healthcare applications.
CUREBench presents two distinct challenges testing both models capabilities and their ability to integrate external tools:
- CUREBench-Internal: Questions designed to test the model's internal medical knowledge and reasoning capabilities without external tool access
- CUREBench-Tools: Questions that require integration with external data sources and tools like medical databases, clinical trial registries, and pharmacological resources
Track 1: CUREBench-Internal - Optimizing Model Performance
Our journey began with systematic evaluation of different models and architectures for the internal benchmark. Here's what we discovered:
Early Experiments: Evaluating MedGemma - a locally deployed, quantized model trained on medical data
Model: Medgemma (local deployment, quantized)
Performance: ~0.45 accuracy
We started by experimenting with Medgemma, a medically-fine-tuned model that we deployed locally using LM Studio on Mac Pro. While the model had relevant medical context, we encountered two major issues: inference was quite slow due to local deployment, and spot checks revealed simple reasoning errors like interpreting "≥60" as ">60". The quantization we applied for faster inference may have contributed to these accuracy issues.
Scaling Up: Cloud-Based Models
We then moved to evaluating frontier cloud-based models:
Gemini Flash
Pushed performance to ~0.65 accuracy - a significant improvement over MedGemma. This was somewhat surprising but consistent with MedGemma Technical Report results.
GPT5 (Azure) & Gemini Pro (Vertex AI)
Both achieved similar performance around 0.65-0.66 with various prompt engineering attempts
Claude Sonnet 4.5 (AWS Bedrock)
Our best single-model performer at ~0.69 accuracy
API Challenges We Encountered
- Rate Limiting: Running ~10 concurrent API calls on Gemini Pro for extended durations triggered API limit errors. We had to throttle requests significantly for Claude Sonnet to avoid hitting limits.
- Safety Filters: A critical discovery - Gemini API's safety settings would refuse to respond to certain medical questions, particularly those around pregnancy and fetal health. While Vertex AI allows disabling these safety filters, the standard Gemini API does not provide this option, making it unsuitable for comprehensive medical question answering.
The Breakthrough: Ensemble Methods
Our key insight came when we evaluated consistency across models. We found that individual models showed only 60-70% consistency when asked the same question. This led us to explore ensemble approaches, building on recent research demonstrating that ensemble methods can significantly improve medical AI performance [1,2]:
Static Majority Voting
When all three models (GPT5, Gemini Pro, Claude Sonnet 4.5) agreed on an answer, we used that response. For questions with disagreement, we applied simple majority voting. This approach improved accuracy beyond any single model.
Dynamic Weighted Majority Voting
For questions where models disagreed, we sampled additional responses and experimented with different model weights. We discovered that giving higher weight to Claude Sonnet 4.5 responses and lower weight to Gemini responses yielded the best results.
This dynamic majority voting approach pushed us to the top of the public leaderboard!
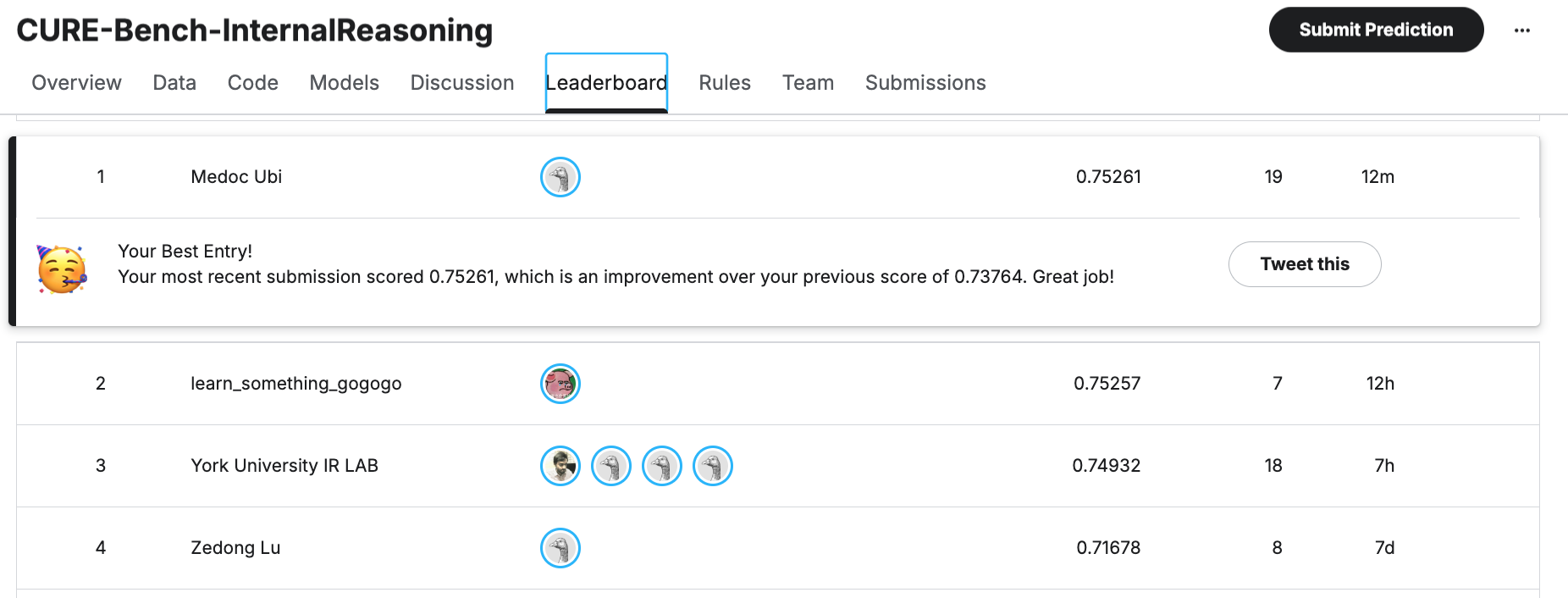
CUREBench-Internal Public Leaderboard - Our top ranking using dynamic weighted majority voting
What Didn't Work: Multi-Agent Discussions
We were hopeful that enabling AI agents to discuss and debate answers by providing each other's responses would improve accuracy. Unfortunately, agents tended to give excessive weight to other models' responses and frequently changed their answers, often moving away from correct responses. We also tried providing all responses to Claude Opus for final judgment, but this didn't yield significantly better results than our weighted voting approach.
Track 2: CUREBench-Tools - Mastering External Integration
The tools track presented new challenges: models needed to not just have medical knowledge, but also effectively use external data sources. Our approach here was methodical and focused on token efficiency.
Strategic Tool Selection
We started with ~14 MCP servers providing numerous overlapping tools. Rather than guess which tools would be most valuable, we took an empirical approach:
- 1. Manual Curation: Based on the competition description, we manually selected MCP servers including OpenFDA, ClinicalTrials.gov, Open Targets, and several others as our initial candidates.
- 2. Usage Analysis: We ran Gemini Flash Lite with all tools enabled and instrumented our system to track tool call frequency across a sample of questions.
- 3. Pareto Distribution: We discovered a highly skewed distribution - one tool accounted for ~70% of calls, the next ~20%, and in total fewer than 15 tools were actively used.
- 4. Focused Deployment: We narrowed our production system to this core set of frequently-used tools, reducing complexity and potential for errors.
Model Performance with Tools
Primary Approach: Gemini Flash with Tools
We used Gemini Flash as our primary tool-using model for most questions. Its balance of speed and accuracy made it ideal for tool-augmented queries.
For questions where models disagreed significantly, we escalated to GPT5 with tools. For the most challenging questions with high inter-model disagreement, we also deployed Claude Sonnet 4.5 with tools.
Gemini Flash with Google Search
Performance: ~0.69 accuracy
Spot checks revealed that results closely matched what we get from Google AI search responses. We also experimented with Gemini Deep Search but didn't observe meaningful improvement.
Claude with Web Search and Tools
Showed strong performance, particularly for complex queries requiring synthesis of multiple data sources.
The RAG Advantage
Next performance jump came when we implemented Retrieval-Augmented Generation (RAG) to improve response consistency [3,4]:
Dynamic Majority Voting with Tools
Just as with the internal benchmark, we applied dynamic weighted majority voting to tool-augmented responses. By adjusting weights based on question difficulty and model confidence, we achieved further improvements in accuracy.
Open Source Models: Promise and Challenges
We also experimented with open-source models for tool use:
Seed-OSS (36B parameters)
Surprisingly, Seed-OSS would claim to use tools in its responses but our experimentation showed minimal actual tool calls. The model appeared to "hallucinate" tool usage rather than executing real API calls.
Nemotron (9B parameters)
Nemotron actually called tools, but its behavior was highly sensitive to prompt engineering. We observed dramatic differences in tool usage patterns based on prompt wording.
Key insight: Using strong directive language like "Your response will not be valid without tool calls" increased tool usage by 3x. This suggests smaller models need more explicit instruction to reliably use tools.
Unfortunately, we didn't have sufficient time to fully optimize open-source models with multiple sampling strategies and advanced prompting techniques.
Final Results: Tools Track
Our approach achieved 5th place on the CUREBench-Tools public leaderboard. We could have potentially improved further by using tools for all questions and employing more extensive multi-model sampling, but we were approaching diminishing returns with steeply rising inference costs.
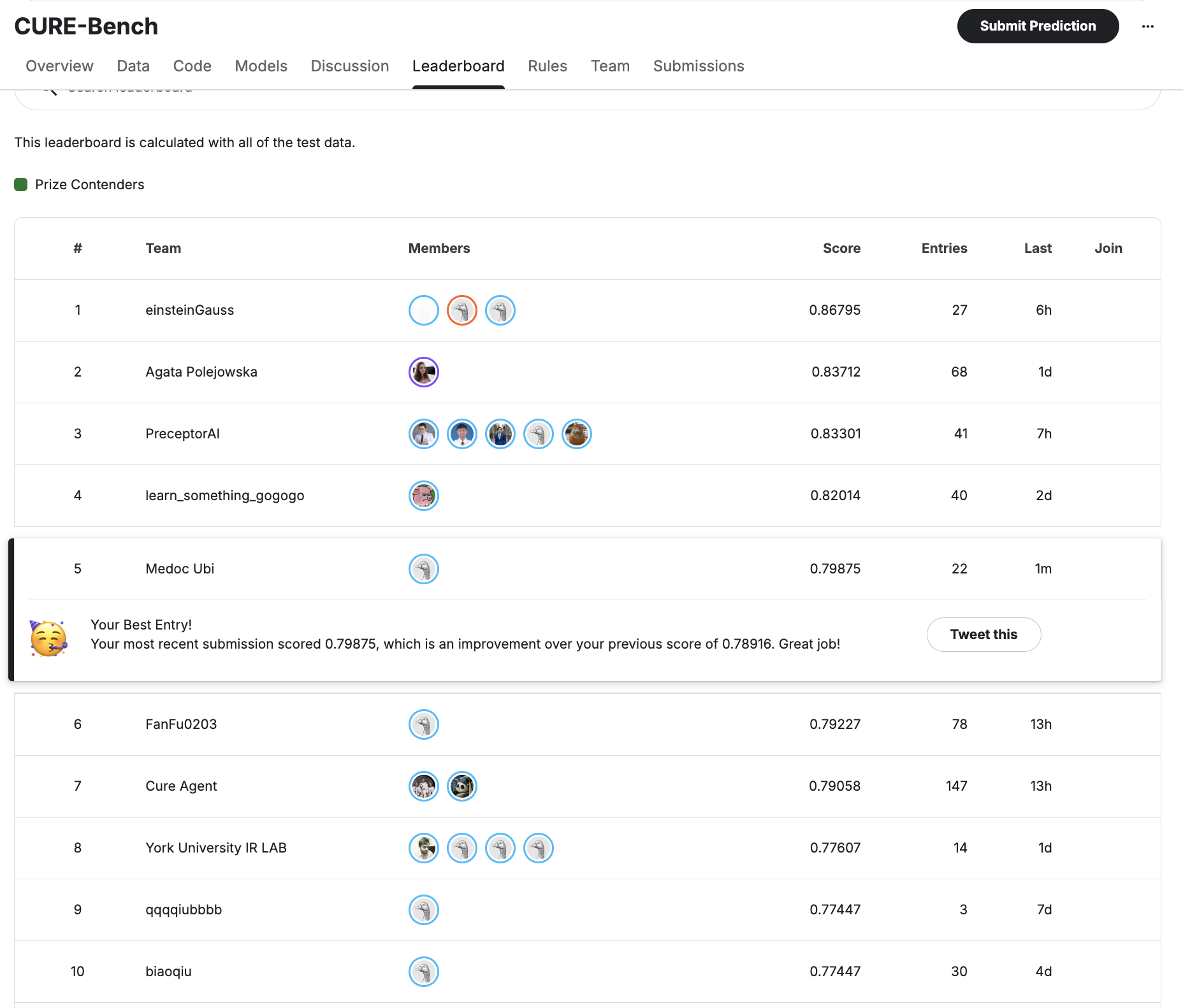
CUREBench-Tools Public Leaderboard - Our 5th place ranking using ensemble methods with strategic tool integration
Technical Challenges and Lessons Learned
Token Tracking with LiteLLM
We used LiteLLM as a unified interface across different model providers, but found token tracking to be inconsistent across providers. Accurate token counting is crucial for both cost management and understanding model behavior. We also encountered issues with using specialized features like Google Search grouding.
Recommendation: Implement custom token tracking alongside LiteLLM's built-in metrics.
CSV Export Challenges
Converting model responses to CSV format for Kaggle submission was surprisingly painful. Special characters, quotes, newlines, and medical terminology with commas required extensive special handling and validation.
Avoiding Batch Processing and Prompt Caching
We deliberately avoided using batch APIs and prompt caching, despite potential cost savings. Our concern was preventing any unintended information spillover between questions.
Rationale: With so many experimental hypotheses to test, we prioritized isolation between runs over optimization. In production systems with stable prompts, these optimizations would be valuable.
Key Takeaways for Medical AI Systems
1. Ensemble Methods Matter
No single model dominated across all medical questions. Dynamic weighted ensembles significantly outperformed individual models, especially on challenging cases.
2. Model Consistency is Critical
The 60-70% consistency rate we observed highlights the need for multiple sampling and validation, especially for high-stakes medical applications.
3. Strategic Tool Selection
Data-driven tool selection (based on actual usage patterns) proved more effective than intuition. The Pareto distribution of tool usage suggests focusing on a core set of high-value integrations.
4. RAG for Consistency
RAG significantly improved response consistency and grounding in authoritative sources - essential for medical AI systems where accuracy is paramount.
5. API Limitations in Practice
Real-world deployment requires careful consideration of rate limits, safety filters, and API vs. platform-specific interfaces (e.g., Gemini API vs. Vertex AI).
6. Open Source Potential
Smaller open-source models show promise for tool use but require careful prompt engineering and may benefit from fine-tuning on tool-calling behavior.
Looking Ahead: Private Leaderboard and Beyond
As we await the private leaderboard results (evaluated on a held-out test set), we're reflecting on what this competition taught us about building reliable medical AI systems:
- Robustness over Peak Performance: Consistent, reliable performance across diverse questions matters more than achieving the highest score on any single question type.
- Cost-Accuracy Tradeoffs: In real applications, we need efficient strategies that balance accuracy with computational cost. Our dynamic escalation approach (starting with faster models, escalating to more powerful ones only when needed) proved effective.
- Tool Integration is Hard: Effectively using external tools requires more than just providing API access - it requires training models to know when and how to use tools appropriately.
- Infrastructure Matters: Robust logging, error handling, and data serialization are as important as model selection for production medical AI systems.
Implications for Drug Discovery and Biotech
Our work on CUREBench directly informs how we build AI systems for drug discovery at UniBio Intelligence. Recent advances in biomedical AI agents like Biomni [7] and TxAgent [8] demonstrate the potential for AI systems to autonomously perform diverse biomedical research tasks, from target identification to therapeutic reasoning:
- Multi-Model Validation: For critical decisions in drug discovery (target selection, toxicity assessment, clinical trial design), we use ensemble approaches with multiple specialized models.
- Curated Tool Integration: Our MCP servers for OpenFDA, Clinical Trials, Open Targets and other biomedical databases are carefully selected based on actual usage patterns in drug discovery workflows.
- Consistency Validation: We implement consistency checks across multiple runs to flag low-confidence predictions that require human expert review.
Open Questions and Future Work
Several interesting questions emerged from this competition that we're continuing to explore:
Can we predict when to use tools vs. internal knowledge?
Building a meta-model that decides whether a question requires tool access or can be answered from internal knowledge could significantly reduce latency and costs.
How do we make multi-agent collaboration work?
Our initial attempts at agent discussions didn't improve accuracy, but more structured debate protocols might yield better results.
Can we use a systematic approach to improve prompts?
Prompts can be improved using a data driven approach - analyzing which prompt styles lead to better tool usage and accuracy could inform automated prompt optimization e.g. Genetic Pareto (GEPA) optimization.
How do we optimize cost-accuracy frontiers?
More sophisticated routing strategies (cheap models for easy questions, expensive models for hard ones) could dramatically reduce costs while maintaining accuracy.
Conclusion: Building Trust in AI
The CUREBench competition reinforced a fundamental truth about medical AI: achieving high performance requires not just powerful models, but careful system design, robust validation, and strategic integration of external knowledge sources.
At UniBio Intelligence, we're applying these lessons to build AI systems that biotech researchers can trust. Whether you're identifying drug targets, designing clinical trials, or analyzing experimental results, our tools combine:
- Multi-model validation for robust predictions
- Curated access to authoritative biomedical databases via MCP servers
- RAG-based grounding in current scientific literature
- Transparent reasoning and source attribution
We're excited to see how the private leaderboard results turn out and look forward to continuing to push the boundaries of what's possible with AI in biomedicine.
Want to Learn More?
Interested in how we're applying these techniques to drug discovery? Check out our other blog posts:
- What is Model Context Protocol? A Guide for Biotech Researchers
- Accelerating Drug Discovery with Open Targets and Antibody Registry MCP Servers
- Protein Structure Prediction with Boltz-2 MCP Server
Have questions about our approach or want to discuss collaboration? Reach out at contact@unibiointelligence.com
Citing This Work
If you found this analysis helpful or reference insights from this work, please cite:
@misc{ubi2025curebench,
author = {UniBio Intelligence},
title = {Our Journey to the Top of CUREBench@NeurIPS 2025: A Deep Dive into Medical AI Benchmarking},
year = {2025},
url = {https://unibiointelligence.com/blog/curebench-neurips-2025},
note = {Accessed: 2026-05-12}
}References
[1]
Jiang, L. Y., Liu, X. C., Nejatian, N. P., Nasir-Moin, M., Wang, D., Abidin, A., Eaton, K., Riina, H. A., Laufer, I., Punjabi, P., Miceli, M., Kim, N. Y., Orillac, C., Schnurman, Z., Livia, C., Kurland, H., Neifert, S., Dastagirzada, Y., Kondziolka, D., Cheung, A. T., Yang, G., Cao, M., Flores, M., Costa, A. B., & Altschul, D. (2024). Large Language Model Synergy for Ensemble Learning in Medical Question Answering. Journal of Medical Internet Research, 27, e70080. https://pmc.ncbi.nlm.nih.gov/articles/PMC12337233/
[2]
Gu, Y., Deng, S., Dredze, M., Rosenberg, E., & Radev, D. (2023). Large Language Models Vote: Prompting for Rare Disease Identification. arXiv preprint arXiv:2308.12890. https://arxiv.org/abs/2308.12890
[3]
Kim, D., Kang, M., Lee, D., Park, J., & Choi, E. (2024). Retrieval-Augmented Generation for Generative Artificial Intelligence in Medicine. npj Health Systems. https://www.nature.com/articles/s44401-024-00004-1
[4]
Zhou, Y., Zeng, J., Zhang, Y., & Chen, H. (2024). Enhancing medical AI with retrieval-augmented generation: A mini narrative review. PMC. https://pmc.ncbi.nlm.nih.gov/articles/PMC12059965/
[5]
Jin, Q., Dhingra, B., Liu, Z., Cohen, W. W., & Lu, X. (2021). PubMedQA: A Dataset for Biomedical Research Question Answering. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Medical question answering benchmarks including MedQA provide USMLE-style questions for evaluating models' medical reasoning abilities.
[6]
Pal, A., Umapathi, L. K., & Sankarasubbu, M. (2022). MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering. Conference on Health, Inference, and Learning. https://paperswithcode.com/dataset/medmcqa
[7]
Biomni Consortium. (2025). Biomni: A General-Purpose Biomedical AI Agent. bioRxiv. Biomni is a general-purpose biomedical AI agent that autonomously performs diverse research tasks using 150 specialized tools, 105 software packages, and 59 databases across 25 biomedical domains. https://www.biorxiv.org/content/10.1101/2025.05.30.656746v1
[8]
TxAgent Team, Zitnik Lab. (2025). TxAgent: An AI Agent for Therapeutic Reasoning Across a Universe of Tools. arXiv preprint arXiv:2503.10970. TxAgent leverages multi-step reasoning and real-time biomedical knowledge retrieval across 211 tools for drug decision-making and personalized treatment strategies. https://arxiv.org/abs/2503.10970
[9]
CUREBench Competition. (2025). Competition on Reasoning Models for Drug Decision-Making in Precision Therapeutics. NeurIPS 2025. https://curebench.ai/